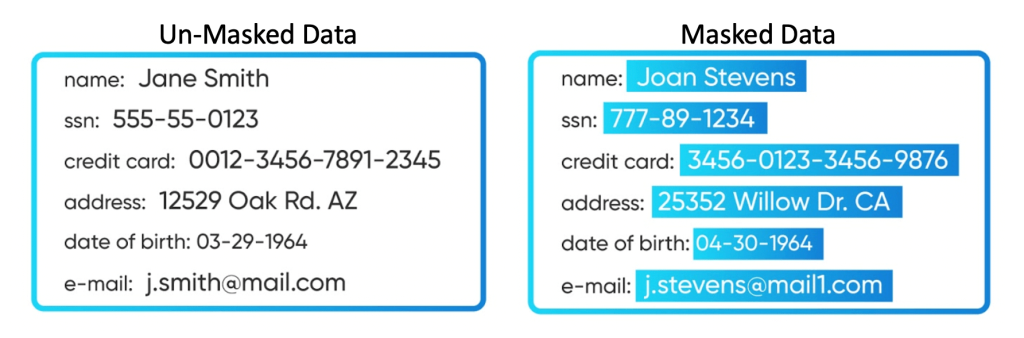
Data masking là một phương pháp được sử dụng để bảo vệ thông tin nhạy cảm bằng cách thay thế dữ liệu thật bằng các dữ liệu giả lập mà không làm mất đi giá trị thông tin. Kỹ thuật này giúp các tổ chức tăng cường bảo mật dữ liệu, giảm rủi ro rò rỉ thông tin và đáp ứng các tiêu chuẩn tuân thủ.
Trong bài viết dưới đây, hãy cùng Nessar tìm hiểu chi tiết về khái niệm Data Masking, tầm quan trọng, các phương pháp phổ biến và ứng dụng thực tế của Data Masking trong doanh nghiệp hiện đại.
Data masking là gì?
Data masking là phương pháp bảo vệ dữ liệu nhạy cảm bằng cách thay thế giá trị gốc bằng một giá trị giả lập nhưng có định dạng và cấu trúc tương tự như thật.
Data masking giúp đảm bảo tính riêng tư cho dữ liệu của tổ chức – đặc biệt là dữ liệu khách hàng – đồng thời hỗ trợ doanh nghiệp tuân thủ các quy định về bảo mật và giảm thiểu rủi ro rò rỉ thông tin.
Data Masking là một thuật ngữ chung bao gồm các kỹ thuật như: anonymization (ẩn danh dữ liệu), pseudonymization (giả danh dữ liệu), redaction (che phủ dữ liệu), scrubbing (làm sạch dữ liệu), de-identification (khử nhận dạng dữ liệu).
Data Masking vs. Data Encryption (Mã hóa dữ liệu)
Mặc dù cả hai cùng hướng đến mục tiêu bảo vệ dữ liệu nhạy cảm, nhưng Data Masking và Data Encryptionphục vụ những mục đích khác nhau:
Data Encryption: làm xáo trộn dữ liệu, khiến dữ liệu chỉ có thể được đọc khi có khóa giải mã
Data Masking: thay thế dữ liệu gốc bằng các giá trị giả lập có định dạng tương tự nhưng không cho phép suy luận hoặc truy xuất ngược về thông tin gốc. Ngoài ra, data masking còn bảo toàn logic và tính liên kết của dữ liệu, rất phù hợp trong các môi trường Dev, kiểm thử và phân tích – cho phép đổi mới một cách an toàn, tuân thủ quy định mà không cần tiết lộ dữ liệu thật.
Data Masking vs. Data Anonymization (Ẩn danh dữ liệu)
Data anonymization sử dụng nhiều kỹ thuật khác nhau như redaction, mã hóa dạng token hoặc tổng hợp dữ liệu nhằm loại bỏ hoặc biến đổi các thông tin nhận dạng cá nhân (PII). Mục tiêu chính của anonymization là ngăn chặn khả năng truy ngược danh tính cá nhân, tuy nhiên dữ liệu đã được ẩn danh thường không duy trì được cấu trúc và mối liên kết logic giữa các trường dữ liệu và mức độ khả dụng cho các mục đích kiểm thử không cao như data masking.
Synthetic Test Data vs. Test Data Masking(Dữ liệu kiểm thử tổng hợp)
Synthetic Test Data (Dữ liệu kiểm thử tổng hợp) là dữ liệu được tạo ra hoàn toàn từ đầu, không dựa trên dữ liệu thật, rất phù hợp trong các trường hợp không thể sử dụng dữ liệu thực tế vì lý do tuân thủ hoặc hạn chế truy cập. Điểm khác biệt lớn nhất giữa hai phương pháp là: Synthetic Test Data được tạo mới hoàn toàn, còn data masking thì bắt nguồn từ dữ liệu thực.
Tại sao Data Masking lại quan trọng?
Phần lớn dữ liệu nhạy cảm trong doanh nghiệp tồn tại ở các môi trường non-production – như môi trường Dev hoặc kiểm thử. Đây chính là bề mặt tấn công lớn nhất, khi mỗi bản dữ liệu gốc có thể có tới 12 bản sao cho mục đích này.
Để kiểm thử hiệu quả, doanh nghiệp cần dữ liệu có tính chân thực. Tuy nhiên, sử dụng dữ liệu gốc tiềm ẩn nguy cơ rò rỉ thông tin nghiêm trọng.
Giải pháp Data masking giúp loại bỏ rủi ro này bằng cách bảo vệ thông tin nhạy cảm và hỗ trợ doanh nghiệp tuân thủ các quy định về bảo mật dữ liệu cá nhân (PII), giúp dữ liệu được chia sẻ nhanh chóng và an toàn đến đúng người, đúng thời điểm.
Câu chuyện thực tế từ ngành y tế
Một công ty y tế tại Mỹ cần chuyển một phần công việc phân tích dữ liệu cho đội ngũ offshore tại Ấn Độ. Tuy nhiên, dữ liệu này bao gồm nhiều thông tin nhận dạng cá nhân (PII) như tên, số an sinh xã hội và lịch sử giao dịch – những dữ liệu không được phép rời khỏi lãnh thổ Hoa Kỳ nếu không có biện pháp bảo vệ thích hợp.
Quá trình triển khai bị đình trệ tranh cãi giữa các phương án xử lý dữ liệu: sử dụng anonymization (ẩn danh dữ liệu) hay redaction (che giấu dữ liệu).
Cuối cùng, công ty quyết định lựa chọn giải pháp Data Masking của Perforce, giúp loại bỏ các thông tin định danh PII mà vẫn giữ nguyên giá trị phục vụ phân tích. Chỉ trong vài phút, dữ liệu đã được xử lý xong và có thể chia sẻ an toàn ra ngoài nước – đồng thời vẫn đảm bảo tuân thủ các quy định nghiêm ngặt về lưu trữ dữ liệu tại Mỹ.
Data Masking không chỉ để bảo vệ dữ liệu – mà còn giúp doanh nghiệp vận hành linh hoạt, không gián đoạn.
Ứng dụng của Data Masking trong các lĩnh vực
Tài chính – Ngân hàng
Các ngân hàng và tổ chức tài chính lưu trữ lượng lớn thông tin nhạy cảm: số tài khoản, điểm tín dụng, lịch sử giao dịch, số an sinh xã hội… Data masking giúp giảm rủi ro lộ lọt dữ liệu nội bộ và đảm bảo tuân thủ các quy định nghiêm ngặt như PCI DSS và GDPR.
Y tế
Các tổ chức y tế thường xuyên phải xử lý những Thông tin sức khỏe được bảo vệ (PHI) như hồ sơ bệnh án, chẩn đoán, thông tin bảo hiểm. Data masking sẽ giúp tuân thủ quy định HIPAA và đảm bảo dữ liệu thật không bị lộ trong môi trường kiểm thử, Dev hay phân tích.
Bán lẻ
Trong lĩnh vực bán lẻ, doanh nghiệp thường xuyên thu thập và xử lý các thông tin nhạy cảm của khách hàng như tên, địa chỉ, thông tin thanh toán và lịch sử mua hàng. Việc áp dụng data masking trong quá trình phát triển và kiểm thử hệ thống giúp ngăn chặn rò rỉ dữ liệu, bảo đảm tuân thủ các quy định bảo mật, đồng thời duy trì lòng tin của người tiêu dùng.
Data Masking qua lăng kính Chuyên gia: Những phân tích đắt giá từ Perforce Delphix
Ngoài ra, báo cáo còn cung cấp nhiều insight thực tiễn về cách triển khai data masking hiệu quả, giúp đảm bảo tuân thủ mà không ảnh hưởng đến chất lượng hay tốc độ xử lý dữ liệu.
Tùy theo mục đích và đặc thù sử dụng, data masking có nhiều phương pháp khác nhau, mỗi loại có ưu điểm riêng:
Data Masking tĩnh: Thay thế vĩnh viễn dữ liệu thật bằng các giá trị giả lập nhưng có định dạng và tính hợp lệ tương tự dữ liệu gốc. Dữ liệu đã được ẩn sẽ được lưu và sử dụng trong các môi trường như dev, test hay phân tích – nơi không cần dữ liệu thật nhưng vẫn cần dữ liệu “trông giống thật” để đảm bảo hệ thống hoạt động bình thường.
Data Masking động: Dữ liệu được che giấu theo thời gian thực khi người dùng truy cập. Các đối tượng không được cấp quyền chỉ nhìn thấy giá trị đã bị làm mờ hoặc thay thế, trong khi dữ liệu gốc vẫn được giữ nguyên trong hệ thống.
Data Masking tức thời: Dữ liệu được che giấu ngay trong quá trình sao chép từ hệ thống production sang hệ thống non-production. Cách này giúp tạo ra môi trường an toàn mà không cần can thiệp vào hệ thống gốc.
Obfuscation (Làm rối dữ liệu): Biến đổi dữ liệu thật sang một định dạng không thể nhận diện, nhưng vẫn giữ nguyên cấu trúc. Kỹ thuật này giúp làm cho dữ liệu vô dụng đối với hacker, trong khi vẫn có thể dùng được cho các bài kiểm thử nội bộ.
Redaction (Che phủ dữ liệu): Loại bỏ hoặc che một phần dữ liệu bằng ký tự thay thế như “X” hoặc “*”. Đây là phương pháp thường dùng khi chia sẻ tài liệu hoặc hiển thị dữ liệu cho người dùng cuối, nhằm bảo vệ các thông tin nhạy cảm.
Scrambling (Xáo trộn dữ liệu): Xáo trộn vị trí các phần tử dữ liệu như ký tự hoặc dòng dữ liệu để làm mất ý nghĩa ban đầu, đồng thời vẫn giữ nguyên độ dài và định dạng dữ liệu. Phương pháp này hỗ trợ kiểm thử phần mềm mà không làm lộ dữ liệu thật.
Tokenization (Mã hóa token): Thay thế dữ liệu nhạy cảm bằng các mã token, các token này được lưu trữ an toàn ở một vị trí riêng biệt, giúp chia sẻ dữ liệu một cách an toàn mà không làm lộ thông tin gốc.
6 yếu tố cần có của một giải pháp Data Masking hiệu quả
Trong môi trường dữ liệu quy mô lớn, không phải giải pháp data masking nào cũng thực sự mang lại giá trị. Sự khác biệt nằm ở việc giải pháp đó chỉ dừng lại ở chức năng cơ bản, hay có thể trở thành một công cụ hiệu quả giúp bảo vệ dữ liệu và tối ưu khả năng sử dụng ở quy mô toàn doanh nghiệp. Dưới đây là những tiêu chí cốt lõi mà một giải pháp data masking hiện đại cần đáp ứng:
1. Đảm bảo tính toàn vẹn tham chiếu
Tính toàn vẹn tham chiếu giúp đảm bảo dữ liệu được masking không bị rời rạc, mất liên kết giữa các hệ thống và tập dữ liệu.
Ví dụ: Nếu thông tin “George” được che giấu thành “Elliot”, thì sự thay thế này phải diễn ra nhất quán trên mọi hệ thống — từ quá trình đánh giá cho đến các hệ quản trị cơ sở dữ liệu khác nhau như Oracle và SQL Server.
Một nhà bán lẻ toàn cầu từng gặp vấn đề nghiêm trọng khi dữ liệu khách hàng được che giấu khác nhau trên từng nền tảng, khiến các dữ liệu phân tích trở nên vô nghĩa cho đến khi họ triển khai một giải pháp đảm bảo sự liên kết giữa các hệ thống.
2. Tạo dữ liệu giả lập thực tế
Giải pháp Data Masking cần có khả năng tạo ra dữ liệu giả nhưng mang tính thực tế — tức là đủ giống thật để phục vụ kiểm thử, nhưng không mang lại giá trị cho kẻ xấu nếu bị rò rỉ. Việc chỉ chuyển tên thành chuỗi ký tự ngẫu nhiên sẽ không đủ. Dữ liệu giả lập cần giữ được ý nghĩa nghiệp vụ phù hợp với mục tiêu phân tích.
Ví dụ: Một tổ chức tài chính từng thay ngày sinh khách hàng bằng giá trị ngẫu nhiên, khiến mô hình phát hiện gian lận bị sai lệch. Khi chuyển sang phương pháp giữ nguyên phân bố độ tuổi, họ vẫn bảo vệ được dữ liệu mà không ảnh hưởng đến phân tích.
3. Không thể đảo ngược
Việc không thể khôi phục dữ liệu gốc từ dữ liệu đã che giấu là yêu cầu bắt buộc, đặc biệt khi dữ liệu được chia sẻ với bên thứ ba hoặc ra bên ngoài.
Thuật toán masking cần được thiết kế để không thể suy ngược lại dữ liệu gốc – kể cả với các công cụ tiên tiến như AI, vốn có khả năng tìm ra mẫu và mối liên hệ rất tinh vi giữa các dữ liệu. Điều này đặc biệt quan trọng trong bối cảnh doanh nghiệp sử dụng dữ liệu để huấn luyện mô hình học máy hoặc AI.
4. Khả năng mở rộng và tích hợp linh hoạt
Khả năng mở rộng và tính linh hoạt đặc biệt quan trọng khi cần triển khai trên nhiều hệ thống khác nhau. Trong khi số lượng nguồn dữ liệu trong pipeline của doanh nghiệp ngày càng tăng nhanh, giải pháp data masking cần tương thích và hoạt động hiệu quả với nhiều loại nguồn dữ liệu mà tổ chức đang sử dụng.
Ví dụ: Một ngân hàng lớn đã sử dụng cách tiếp cận theo chính sách, áp dụng một quy tắc masking duy nhất cho hơn 20 hệ thống – giúp giảm thiểu khối lượng công việc thủ công và rủi ro vận hành.
5. Khả năng lặp lại và tự động hoá
Để quy trình data masking thực sự hiệu quả, giải pháp cần có khả năng tự động và dễ dàng tái diễn mà không phải thiết kế lại mỗi khi xuất hiện bộ dữ liệu mới hoặc thay đổi yêu cầu nghiệp vụ.
Data Masking không phải là tác vụ thực hiện một lần duy nhất. Trong thực tế, doanh nghiệp cần lặp đi lặp lại quy trình này liên tục khi dữ liệu phát sinh hoặc thay đổi theo thời gian. Do đó, công cụ cần đảm bảo tốc độ, khả năng tự động hóa và tích hợp trơn tru vào các quy trình hiện có như SDLC hoặc DevOps.
Nhiều giải pháp hiện nay gây ra gánh nặng vận hành và kéo dài chu kỳ kiểm thử. Ngược lại, với cách tiếp cận tự động, các đội ngũ có thể nhanh chóng nhận diện và che giấu thông tin nhạy cảm như họ tên, email, hoặc dữ liệu thanh toán — giúp tổ chức có cái nhìn toàn diện về rủi ro và xác định chính xác các mục tiêu cần bảo vệ.
6. Quản lý tập trung dựa trên chính sách
Với cách tiếp cận dựa trên chính sách, dữ liệu nhạy cảm có thể được mã hóa token – cho phép truy xuất ngược khi cần – hoặc che giấu vĩnh viễn, tùy theo yêu cầu bảo mật nội bộ và các quy định pháp lý như GDPR,CCPA. Việc triển khai dựa trên chính sách giúp doanh nghiệp dễ dàng xác định, quản lý và áp dụng các quy tắc bảo vệ dữ liệu từ một giao diện tập trung, đồng bộ trên toàn bộ hệ thống dữ liệu lớn, đa dạng và phức tạp – theo thời gian thực.
Lợi ích của Data Masking
Trong kỷ nguyên số, khách hàng ngày càng quan tâm đến quyền riêng tư và yêu cầu cao hơn trong việc bảo vệ thông tin cá nhân. Đồng thời, doanh nghiệp cũng cần khai thác dữ liệu một cách an toàn để phục vụ đổi mới, tối ưu trải nghiệm người dùng và phát triển sản phẩm.
Khi được triển khai đúng cách, Data Masking giúp doanh nghiệp che giấu nội dung dữ liệu nhạy cảm mà vẫn giữ nguyên giá trị sử dụng cho mục đích kinh doanh. Giải pháp này hỗ trợ duy trì tính toàn vẹn tham chiếu giữa các cơ sở dữ liệu, đáp ứng yêu cầu tuân thủ các quy định về bảo mật thông tin và giảm thiểu nguy cơ rò rỉ dữ liệu.
Đặc biệt, Data Masking có thể được triển khai mà không cần kỹ năng lập trình chuyên sâu, cho phép tổ chức chia sẻ dữ liệu trong môi trường non-production hoặc cloud một cách an toàn, đồng thời hạn chế tối đa mức độ phơi nhiễm trước các mối đe dọa.
Xem video bên dưới để khám phá thêm lợi ích của data masking đối với đội ngũ Dev
Case Study: 3 Doanh nghiệp ứng dụng Data Masking của Perforce Delphix để đảm bảo tuân thủ và tối ưu hiệu suất
Nhiều tổ chức trên toàn cầu đã lựa chọn giải pháp Data Masking của Perforce Delphix nhằm tự động hóa quá trình bảo vệ dữ liệu, mở rộng quy mô linh hoạt, đảm bảo tuân thủ quy định và tăng tốc đổi mới. Dưới đây là cách Molina Healthcare, Morningstar Retirement, và Choice Hotels đã nâng cao bảo mật và hiệu quả vận hành nhờ vào Data Masking của Perforce Delphix:
Y tế: Molina Healthcare
Molina Healthcare triển khai Data Masking của Perforce Delphix để tự động bảo vệ PHI trên hàng ngàn cơ sở dữ liệu non-production, đáp ứng nghiêm ngặt yêu cầu tuân thủ HIPAA và đồng thời tinh gọn quy trình phát triển ứng dụng.
Nhờ tích hợp khả năng che giấu dữ liệu và cấp phát môi trường tự động của Delphix, Molina rút ngắn thời gian thiết lập môi trường xuống dưới 10 phút, giảm 50% thời gian triển khai các dự án ứng dụng và tiết kiệm đến 4PB dung lượng lưu trữ.
Morningstar Retirement sử dụng Perforce Delphix để tự động hóa quản lý dữ liệu thử nghiệm an toàn và đảm bảo tuân thủ tiêu chuẩn SOC 2.
Việc ứng dụng giải pháp của Perforce Delphix đã giúp Morningstar giảm 70% thời gian cấp phát dữ liệu, cải thiện chất lượng phần mềm nhờ phát hiện lỗi sớm hơn, và cho phép đội ngũ Dev tập trung vào tính năng mới và tăng cường bảo mật hệ thống.
Choice Hotels ứng dụng Perforce Delphix để bảo vệ thông tin khách hàng nhạy cảm đồng thời tăng tốc phát triển ứng dụng. Với giải pháp của Perforce Delphix, doanh nghiệp đảm bảo tuân thủ quy định, tinh gọn quy trình cấp phát dữ liệu thử nghiệm, và giúp đội ngũ cải tiến một cách an toàn mà không ảnh hưởng đến quyền riêng tư dữ liệu.
Tự động hóa và mở rộng Data Masking với Perforce Delphix
Perforce Delphix mang đến giải pháp data masking tự động và dễ dàng mở rộng trên quy mô doanh nghiệp. Giải pháp giúp giảm thiểu rủi ro, đảm bảo tuân thủ các quy định về bảo mật dữ liệu cá nhân, đồng thời thúc đẩy đổi mới an toàn trong các quy trình DevOps và ứng dụng AI.
Khả năng phát hiện dữ liệu nhạy cảm nâng cao
Perforce Delphix tự động xác định và phân loại dữ liệu nhạy cảm trên toàn bộ hệ thống — bao gồm tên, địa chỉ email, thông tin thanh toán — từ đó giúp doanh nghiệp đánh giá chính xác mức độ rủi ro và xác định đúng đối tượng cần che giấu.
Che giấu dữ liệu tự động
Perforce Delphix sử dụng phương pháp data masking tĩnh để chuyển đổi vĩnh viễn dữ liệu nhạy cảm thành các giá trị giả lập nhưng vẫn mang tính logic, đảm bảo phục vụ hiệu quả cho các hoạt động Dev, test, phân tích và huấn luyện AI.
Không giống như các phương pháp mã hóa có thể giải mã ngược, Perforce Delphix đảm bảo dữ liệu sau khi được che giấu sẽ không thể bị khôi phục, cung cấp một lớp bảo vệ vững chắc trong môi trường non-production.
Tích hợp linh hoạt và quản trị tập trung
Perforce Delphix dễ dàng tích hợp với các quy trình DevOps và tuân thủ hiện có, đồng thời hỗ trợ triển khai rộng rãi trên các hệ thống dữ liệu phức tạp — từ mainframe cho đến cloud-native. Doanh nghiệp có thể thiết lập, quản lý và thực thi chính sách bảo mật tập trung cho toàn bộ dữ liệu phi sản xuất.
Với sự kết hợp giữa tự động hóa, khả năng tích hợp cao và quản trị tập trung, Delphix giúp doanh nghiệp:
Thiết lập, quản lý và áp dụng chính sách bảo mật và tuân thủ một cách tập trung
Giảm tới 77% nguy cơ rò rỉ dữ liệu nhạy cảm
Rút ngắn thời gian phát hành ứng dụng gấp đôi so với thông thường
📩 Liên hệ với Nessar ngay để được tư vấn chi tiết về nền tảng Perforce Delphix DevOps Data Platform và giải pháp Data Masking: